梯度
上次说的resnet为啥要两个精度,是让损失平面变的光滑,课p35讲了
常见函数的梯度
激活函数
Mean Squared Error均方差
- 使用grad()
x=torch.ones(1)
w=torch.full([1],2).float()
w.requires_grad_()
mse=F.mse_loss(torch.ones(1),x*w)
# 更新需要计算梯度,或者初始化时设置requires_grad=True
torch.autograd.grad(mse,[w])
43
(tensor([2.]),)
- 使用backward()
x=torch.ones(1)
w=torch.full([1],2).float()
w.requires_grad_()
mse=F.mse_loss(torch.ones(1),x*w)
# 更新需要计算梯度,或者初始化时设置requires_grad=True
# torch.autograd.grad(mse,[w])
mse.backward()
w.grad
44
tensor([2.])
使用backward后,grad会存储在w里
Cross Entropy Loss
softmax(soft version of max)
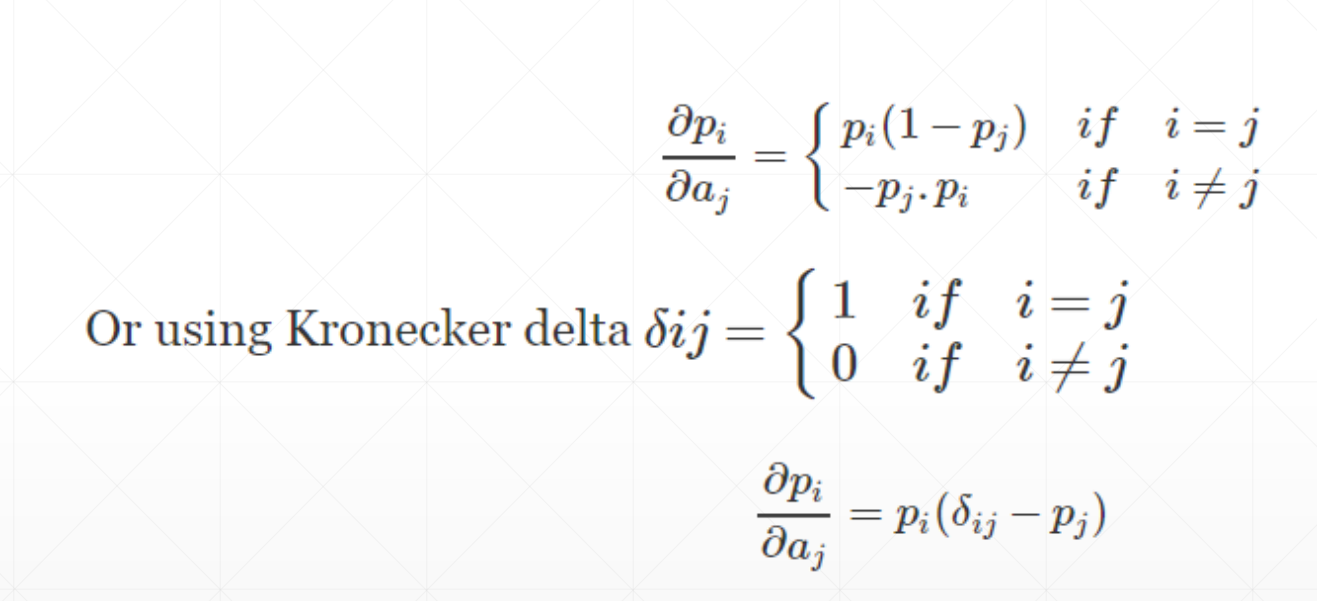
a=torch.rand(3)
a.requires_grad_()
p=F.softmax(a,dim=0)
print(p)
# p.backward()
torch.autograd.grad(p[1],[a],retain_graph=True)
tensor([0.2106, 0.5013, 0.2881], grad_fn=<SoftmaxBackward0>)
47
(tensor([-0.1056, 0.2500, -0.1444]),)